 Technology Turn Paper Documents Digital")
Introduction
Optical character recognition technology bridges the gap between physical documents and the digital world. Unlike many digital transformation tools, OCR specifically targets the conversion of printed and handwritten text into a machine-readable format, making it a cornerstone of modern document management systems.
Did you know that OCR technology can process 10,000 documents with only 1-4 errors, while humans make 100-400 mistakes processing the same volume?
Modern optical character recognition (OCR) solutions achieve up to 99% accuracy in transforming printed and handwritten documents into digital text. That’s why businesses across retail, finance, healthcare, education, and legal sectors are embracing this technology to revolutionize their document processing.
Consider this: While a data entry professional costs $17.66 per hour, OCR software subscriptions run around $20 monthly. However, the benefits go beyond cost savings – tasks that took days now complete in hours, making previously inaccessible data available at a click.
Ready to discover how optical character recognition (OCR) can transform your paper documents into valuable digital assets? Let’s dive into everything you need to know about this powerful technology.
What is Optical Character Recognition (OCR) and Why It Matters Today
Definition of Optical Character Recognition (OCR)
Optical Character Recognition (OCR) is the electronic or mechanical conversion of images containing text into machine-encoded, editable text. This technology analyzes the pixels of an image and transforms them into searchable and editable data. OCR goes beyond simple digitization by enabling computers to recognize and interpret the characters present in document images.
Technology works through a sophisticated process involving pre-processing, segmentation, recognition, and post-processing. During pre-processing, the image is cleaned of noise and adjusted for contrast and brightness. Segmentation breaks down the image into smaller components like characters and lines. Recognition then matches these segments to defined characters using pattern matching and feature extraction techniques.
What makes optical character recognition particularly valuable is its ability to handle diverse text sources. Beyond standard documents, OCR can process text from photos, scene images (like text on billboards), and even subtitle text superimposed on images. Furthermore, advanced OCR systems can reproduce formatted output that closely approximates the original page, preserving images, columns, and other non-textual components.
How OCR differs from simple scanning
Many people confuse scanning with OCR, yet they serve fundamentally different purposes. Scanning a document is essentially taking a picture of it, creating a digital image that visually represents the original document. Although convenient for storing digital copies, scanned documents without optical character recognition remain as images where the text cannot be edited, searched, or manipulated.
The key distinction lies in what happens after digitization. When you scan a document, you end up with an image file where the text is locked within pixels. Consequently, you cannot search for specific words or edit the content. optical character recognition, on the other hand, analyzes these images to identify and extract the characters, converting them into machine-readable text that can be edited in word processors.
This difference becomes especially significant when dealing with large volumes of paperwork. As one source points out: “Imagine going through this process with high volumes of data and the paperwork that follows them”. OCR eliminates the tedium of manual data entry from scanned documents, reducing both time investment and human error.
For businesses integrating Electronic Data Interchange (EDI) systems, OCR provides exceptional value by enhancing electronic invoice processing. When integrated with EDI workflows, OCR technology can automatically capture and validate documents, transforming paper invoices into structured digital data. This integration dramatically reduces delays in processing, improves compliance with business rules, and creates a more seamless exchange of information between trading partners.
Common formats OCR can process
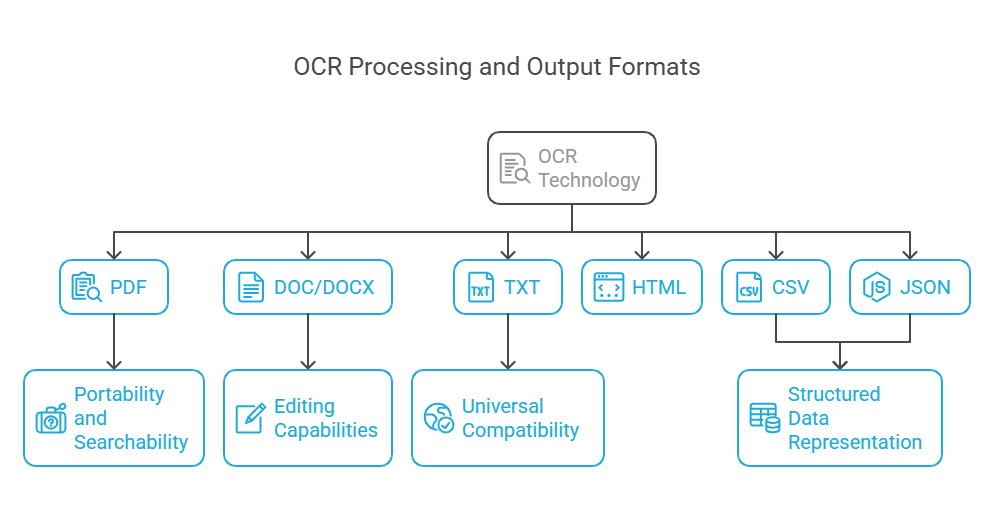
OCR technology demonstrates remarkable versatility in handling various document types and producing different output formats based on business needs.
The most common output formats from OCR processing include:
- PDF: The most widely used format that maintains document appearance while making text searchable
- DOC/DOCX: Editable word processing formats ideal for content that requires modification
- TXT: Simple text format that’s universally compatible and easily searchable
- HTML: Web-friendly format useful for online publishing
- CSV: Comma-separated values format is particularly valuable for structured data
- JSON: Machine-friendly format that represents data in a structured way, making it excellent for further processing
Each format offers distinct advantages depending on your needs. PDF files provide excellent portability and searchability while preserving document appearance. DOC files enable extensive editing capabilities. TXT files offer universal compatibility. JSON and CSV formats excel at structured data representation for integration with databases and analytics systems.
Beyond output formats, optical character recognition systems can process numerous input sources. These include scanned paper documents, digital photos containing text, PDFs without text layers, invoices, tax documents, business cards, and even handwritten forms. Modern OCR solutions can also handle multilingual content, catering to global business requirements.
The ability to process these diverse formats makes OCR an essential tool for businesses looking to digitize their document workflows. Additionally, when combined with Electronic Data Interchange systems, OCR enables seamless conversion of paper-based information into structured electronic formats, facilitating more efficient business transactions and document exchange.
How Optical Character Recognition (OCR) Works: From Image to Editable Text
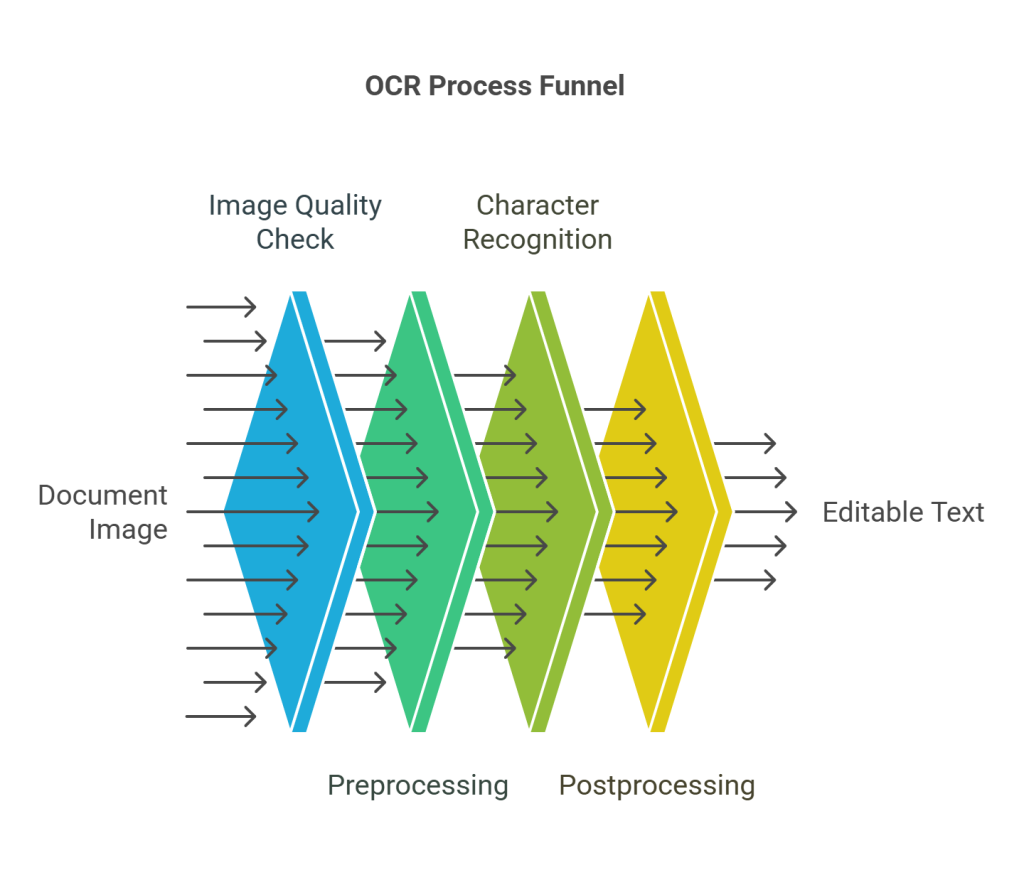
Transforming physical documents into digital text involves a complex series of operations that work together to deliver accurate results. Understanding the inner workings of OCR technology reveals why it’s so effective at bridging the gap between paper and digital formats.
Step 1: Image input and quality check
The optical character recognition (OCR) process begins with capturing the document through scanning or photography. This initial step significantly impacts the final accuracy of text recognition. Since OCR software analyzes dark areas as text and light areas as background, proper image acquisition ensures optimal character identification.
Quality checks at this stage involve verifying image resolution, checking for proper alignment, and ensuring adequate contrast between text and background. According to research, the foundation of accurate OCR lies in the quality of input images, as poor-quality images with blurry text, low contrast, or complex backgrounds pose serious challenges to OCR systems.
For businesses integrating OCR with Electronic Data Interchange (EDI) systems, this quality assessment step is crucial. When processing invoices or purchase orders through EDI, clear initial scans minimize data extraction errors, resulting in fewer exceptions requiring manual intervention.
Step 2: Preprocessing and noise reduction
Before actual character recognition begins, OCR systems apply sophisticated preprocessing techniques to enhance image quality. This vital step transforms raw input into optimized images ready for accurate text extraction.
The preprocessing stage typically includes:
- De-skewing: Correcting document tilt by rotating the image to align text horizontally or vertically
- Binarization: Converting grayscale or color images to black-and-white, creating maximum contrast between text and background
- Noise removal: Eliminating specks, smudges, and other marks that could interfere with character recognition
- Line removal: Cleaning up non-text elements like boxes and lines
- Layout analysis: Identifying distinct blocks such as columns, paragraphs, and captions
For EDI document processing, this preprocessing stage is particularly valuable when handling supplier invoices of varying quality. By standardizing document appearance through preprocessing, OCR technology ensures consistent data extraction regardless of the original document format.
Step 3: Character recognition techniques
Once preprocessing is complete, OCR systems employ two primary methods to identify text:
- Pattern matching (Matrix matching): This technique compares each character image with stored glyphs on a pixel-by-pixel basis. While efficient for standard fonts, pattern matching struggles with new or unusual typefaces.
- Feature extraction: This more sophisticated approach breaks down characters into components like lines, loops, line direction, and intersections. By analyzing these distinctive features, OCR systems can recognize a wider variety of fonts and styles.
Advanced OCR systems often use a two-pass approach. Initially, they identify characters with high confidence, then use that information to better recognize remaining characters during a second passage technique known as adaptive recognition.
When integrated with EDI workflows, these recognition techniques enable automatic extraction of critical information such as invoice numbers, dates, line items, and totals from supplier documents, eliminating manual data entry into EDI systems.
Step 4: Postprocessing and error correction
Despite advances in OCR technology, recognition errors still occur. Postprocessing steps help identify and correct these inaccuracies before delivering the final text output.
Modern OCR systems employ several error correction methods:
- Lexicon constraints: Comparing extracted words against allowed vocabularies
- Near-neighbor analysis: Examining co-occurrence frequencies to identify likely word combinations
- Grammar analysis: Using language rules to determine if words are likely nouns, verbs, etc.
- Machine learning algorithms: Applying trained models to detect and correct common OCR errors
For EDI integration, this error correction phase is critical. Research shows that post-processing approaches for correcting OCR errors typically involve two steps: detection and correction. Recent studies demonstrate that systems based on n-gram counts of candidate tokens have achieved state-of-the-art F1-scores across multiple European languages, with improvements from 0.69 to 0.90 for Spanish text.
When applied to electronic invoice processing, these postprocessing techniques ensure that extracted data is validated against expected formats before entering EDI systems, reducing exceptions and improving straight-through processing rates.
Types of OCR Technology and Their Use Cases
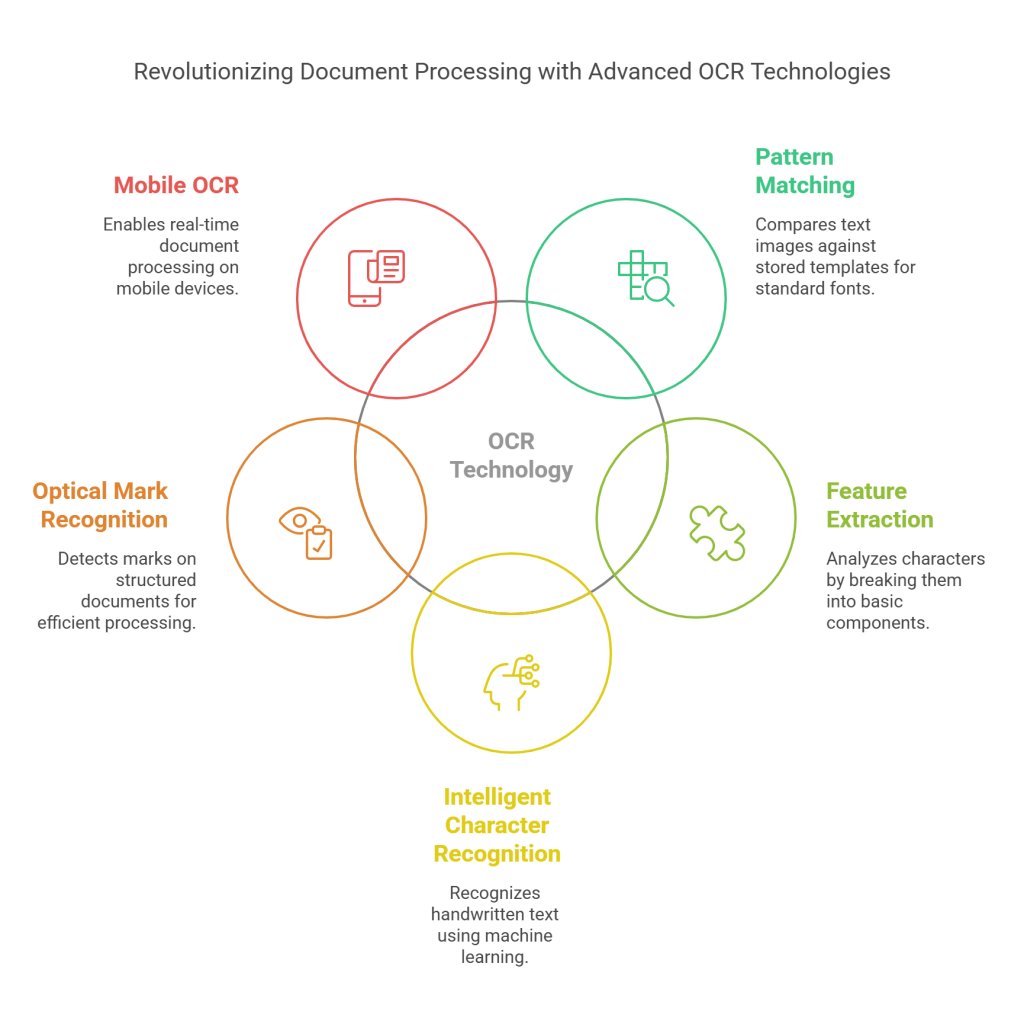
Various optical character recognition (OCR) technologies exist today, each designed to address specific document processing challenges. Modern systems employ different recognition techniques and specialized functions that make them suitable for industries and document types.
1. Pattern Matching vs. Feature Extraction
Pattern matching and feature extraction represent two fundamental approaches to OCR technology. Pattern matching operates through a straightforward process—comparing text images character by character against stored templates of fonts and patterns. This method works efficiently with standard fonts but faces limitations with new or unusual typefaces since it cannot possibly store every font variation.
Conversely, feature extraction breaks down characters into their basic components like lines, curves, intersections, and loops. Rather than comparing entire characters, this approach analyzes these distinctive elements. Feature extraction typically relies on machine learning algorithms such as k-nearest neighbors to find the best matches after detecting these features. The method proves more versatile for identifying both printed text and complex handwritten documents compared to pattern matching.
For EDI (Electronic Data Interchange) systems, feature extraction techniques deliver superior results when processing supplier invoices with varying fonts and formats. This enhances straight-through processing rates for electronic invoices by accurately capturing line items, totals, and reference numbers despite formatting variations.
2. Intelligent Character Recognition (ICR)
ICR represents a significant advancement over basic OCR, specifically engineered to recognize handwritten text. This technology excels at interpreting different handwriting styles and fonts through sophisticated neural networks. Unlike traditional OCR, ICR employs machine learning that allows it to improve continuously, learning from each new text sample it processes.
Most ICR software contains self-learning systems that automatically update recognition databases for new handwriting patterns. Through this learning capability, some systems achieve remarkable 97%+ accuracy rates when reading handwriting in structured forms.
Industries benefiting from ICR integration with EDI include:
- Healthcare (patient intake forms)
- Banking (loan applications, KYC forms)
- Insurance (claims processing)
- Real estate (contract agreements)
When combined with EDI workflows, ICR eliminates manual data entry from handwritten forms, creating a seamless bridge between paper documents and digital transaction systems.
3. Optical Mark Recognition (OMR)
OMR technologies specifically identify marked responses on structured documents. Rather than recognizing text, OMR detects the presence or absence of marks in designated areas—perfect for processing forms where users make selections by filling in bubbles or checkboxes.
With dedicated OMR devices, hundreds or even thousands of documents can be processed hourly with remarkable accuracy. Modern OMR solutions achieve 99.9% data collection accuracy when working with quality printed forms.
Educational institutions extensively utilize OMR for standardized testing, including SAT, GRE, and other examinations. Moreover, election systems can process up to 200,000 ballots daily using specialized OMR technology, combining CCD line cameras with image processing boards for accurate vote counting.
For EDI integration, OMR provides efficient processing of structured order forms and shipping documents. This combination enables organizations to quickly digitize paper-based ordering systems and incorporate the data into electronic business transactions.
4. Mobile OCR and real-time applications
Mobile OCR represents the newest frontier in optical character recognition, bringing this technology to smartphones and tablets for on-the-go document processing. The mobile OCR market is expanding rapidly, expected to reach USD 13.38 billion by 2025, growing at a CAGR of 13.7% from 2020 to 2025.
Modern mobile scanning apps offer multiple recognition modes for various document types, including books, business cards, ID cards, and even whiteboards. These applications enable real-time text extraction, translation, and processing directly from a mobile device’s camera.
In logistics, mobile OCR facilitates real-time package tracking updates and expedites the processing of shipping documents. Financial applications enable instant check deposits and streamline expense reporting through receipt scanning. When integrated with EDI systems, mobile OCR allows field personnel to capture shipping documents, delivery confirmations, and order forms at the point of transaction, accelerating the entire supply chain process.
Integrating Optical Character Recognition (OCR) Technology with EDI for Smarter Workflows
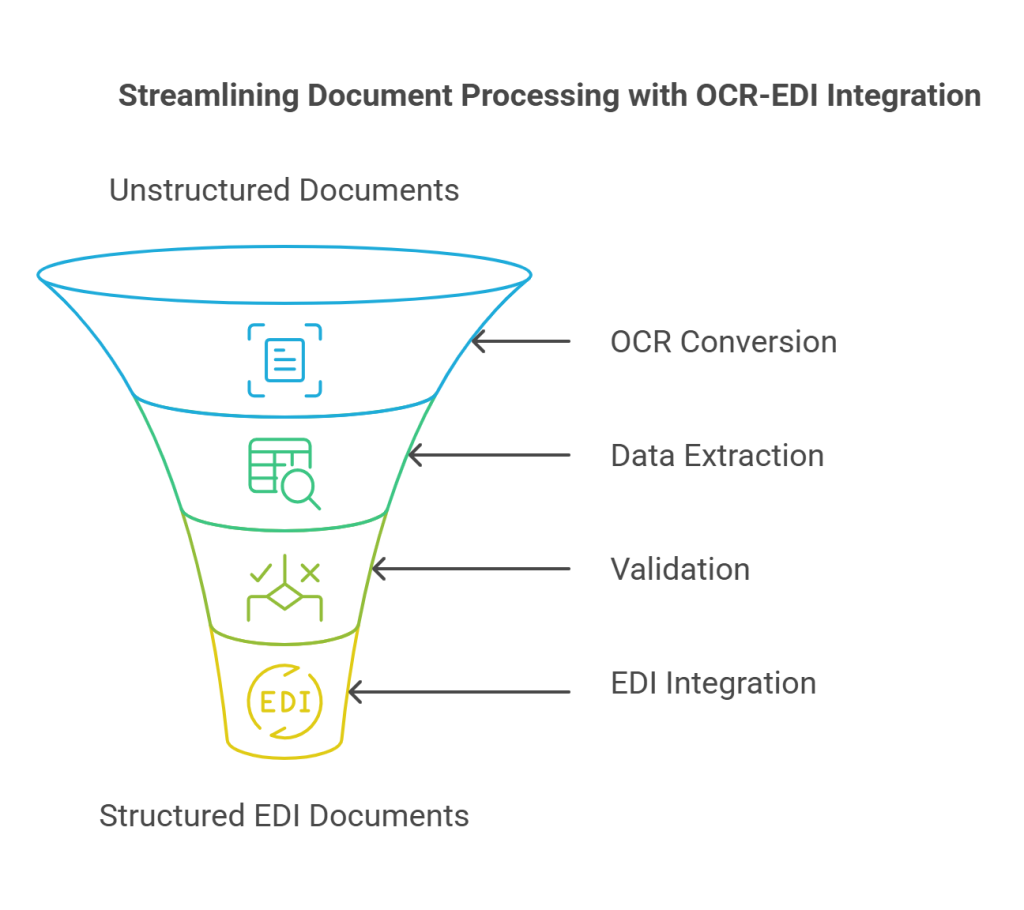
While both optical character recognition (OCR) and EDI optimize business workflows independently, their integration creates a uniquely powerful system for document processing. This strategic combination addresses key challenges in managing structured and unstructured data across trading partner networks.
How OCR enhances electronic invoice processing
OCR technology serves as the initial step in electronic invoice processing, converting physical or digital invoice images into machine-readable text. For businesses already using Electronic Data Interchange (EDI) systems, OCR fills critical gaps in document exchange workflows:
- Unstructured document handling: OCR extracts data from PDFs, removing the need for manual data entry
- Intelligent data extraction: Combined OCR and NLP can interpret complex line items, understanding product codes, quantities, and descriptions
- Validation capabilities: OCR systems flag potential errors or inconsistencies in extracted data, such as mismatched totals or invalid dates
This complementary technology ensures that data flows seamlessly from paper documents into structured EDI formats. Indeed, OCR technology and automated invoice processing are essential to the conversion from manual to electronic processing.
Automating EDI document capture and validation
EDI provides standardized electronic document exchange, yet many companies still receive documents from partners in non-EDI formats. According to factual data, OCR bridges this gap through:
- Hybrid approach implementation: Maintain systems where OCR complements EDI by handling non-standardized or minimal document exchange volumes
- Partner segmentation strategy: Reserve OCR for trading partners who exchange only a few documents monthly and are unlikely to invest in full EDI capabilities
- Data enrichment capabilities: IDI (Intelligent Data Interchange) systems identify, correct, and enrich existing data independently, closing data gaps with high data quality
Most importantly, optical character recognition (OCR) effectively processes occasional documents like one-off invoices or correspondence that would be impractical to handle through full EDI integration.
Reducing delays and improving compliance
The OCR-EDI integration delivers tangible workflow improvements through:
- Faster processing cycles: OCR automates document exchange, leading to quicker order fulfillment and payments
- Error reduction: Minimizes data entry errors, reducing disputes and ensuring smoother transactions
- Stronger compliance: Automated checks ensure invoices meet regulatory and company policy requirements
Together, these technologies create a complete document exchange ecosystem. As the factual data shows, both EDI and OCR can help companies improve business efficiency and reduce operational costs. By strategically utilizing OCR alongside EDI, businesses optimize costs while maintaining flexibility.
Benefits of OCR for Business Operations
Implementing OCR technology delivers tangible operational benefits that transform how businesses handle documents. From streamlining workflows to reducing costs, OCR creates opportunities for organizations to operate more efficiently while freeing employees to focus on higher-value tasks.
1. Faster data entry and reduced manual work
The most immediate advantage of OCR technology is the dramatic reduction in processing time. Tasks that traditionally required extensive manual effort are now completed in a fraction of the time:
- Processing time decreases from 15-20 minutes per document to just 1-2 minutes
- Staff focus shifts notably from 60% time spent on data entry to 85% time available for analysis and decision-making
- Documents that took days to process are now complete in hours
OCR takes over repetitive data entry tasks by automatically extracting information from documents. Presently, businesses using OCR can process large volumes of documents efficiently without requiring manual sorting through each scan. Subsequently, employees can redirect their attention to more strategic activities instead of tedious data input.
For invoice processing specifically, OCR technology scans documents and converts them to searchable PDF files. This process can be completely automated, retrieving data directly from databases without human intervention. When integrated with Electronic Data Interchange (EDI) systems, OCR enhances electronic invoice processing by automating data capture and validation, creating a seamless flow from paper documents to digital workflows.
2. Improved accuracy and fewer errors
Manual data entry inherently introduces mistakes – a missed digit here or an extra character there can cause significant problems. OCR technology addresses this challenge:
OCR reduces error rates from approximately 1 error per 100 keystrokes in manual entry to fewer than 1 error per 1,000 characters. With quality scans, modern OCR solutions achieve up to 99.5% accuracy for tasks like extracting bank statement data.
This improved accuracy is essential when processing critical business documents like invoices, purchase orders, and contracts. Fundamentally, OCR minimizes risks associated with financial discrepancies by accurately capturing vendor details, invoice numbers, dates, and line items.
When combined with EDI, OCR ensures that extracted data undergoes validation against expected formats before entering downstream systems. This integration minimizes exceptions requiring manual intervention and improves straight-through processing rates for electronic transactions.
3. Cost savings and scalability
The financial case for OCR implementation is compelling:
On average, data entry personnel cost approximately $40,504 annually, whereas a year’s worth of OCR software typically runs under $1,000. This substantial difference makes OCR a cost-effective alternative to outsourcing data entry.
Beyond direct labor savings, OCR eliminates expenses related to paper storage, printing, and physical document management. Companies can allocate resources more effectively by automating these processes.
Altogether, OCR technology offers excellent scalability – a crucial advantage as businesses grow. The system can handle increasing document volumes without proportional increases in time or resources. As content managers scale their OCR initiatives to meet current document flows, they can design their implementation to manage larger-than-expected workflows, supporting enterprise growth without adding staff.
For EDI workflows, this scalability is particularly valuable. As transaction volumes increase, the OCR-EDI integration continues processing documents efficiently, maintaining accuracy regardless of volume. This ensures that electronic data exchange remains smooth even during periods of business expansion or seasonal volume spikes.
OCR in Action: Real-World Industry Applications
Across industries, OCR technology is transforming critical business processes through intelligent document automation. Let’s examine how different sectors leverage this powerful tool to streamline operations and enhance productivity.
1. Retail and supply chain optimization
Supply chain operations benefit tremendously from OCR implementation. With high-performance OCR, companies track products throughout the supply chain with remarkable efficiency.
In retail environments, OCR enables:
- Automated receiving: Staff scan shipping documents to capture product details and quantities
- Return processing: OCR scans return labels for integration with digital systems
- Price auditing: Employees scan shelf labels to verify pricing accuracy automatically
When integrated with EDI systems, OCR technology enhances electronic invoice processing by automating data capture from paper documents and validating information before it enters downstream systems. This integration reduces processing delays, improves compliance, and creates seamless information exchange between trading partners.
2. Healthcare records and prescriptions
In medical settings, OCR technology converts paper-based patient information into structured digital formats. Healthcare providers report up to 99% data accuracy when implementing OCR systems for medical records management.
Key healthcare applications include:
- Prescription processing: OCR reads handwritten prescriptions, reducing medication errors
- Patient record digitization: Transforms intake forms and medical histories into searchable files
- Insurance claims: Extracts relevant information from claim forms, accelerating reimbursements
OCR simultaneously improves HIPAA compliance through better document security and accessibility controls.
3. Banking and finance document automation
Financial institutions increasingly deploy OCR to automate KYC processes by extracting data from identity documents, address proofs, and other verification paperwork. JPMorgan Chase implemented AI-based OCR technology for analyzing complex legal documents, saving thousands of hours annually.
Banking applications extend beyond simple digitization:
- Loan processing: OCR accelerates approvals by automatically extracting relevant information from tax returns, income statements, and credit reports
- Identity verification: The technology reads and compares ID documents with customer-input data, minimizing fraud risk
- Signature recognition: OCR systems verify signatures automatically, enhancing document validity checks
Most importantly, OCR enables banks to process customer service requests 60% faster while maintaining data accuracy up to 99.5%.
4. Legal document digitization
Law firms handle enormous document volumes, making OCR particularly valuable. The technology transforms contracts, briefs, and case files into searchable digital assets.
For legal professionals, OCR facilitates:
- Document classification by identifying keywords and document types
- E-discovery processes by enabling text searches across massive datasets
- Contract analysis through automatic extraction of key clauses and terms
Conclusion
OCR technology stands as a game-changing solution for businesses seeking efficient document processing. Through advanced character recognition techniques and sophisticated error correction, modern OCR systems achieve remarkable accuracy rates while significantly reducing operational costs.
The versatility of OCR shines across multiple industries – from banking and healthcare to retail and legal sectors. Each implementation demonstrates substantial improvements in processing speed, data accuracy, and resource allocation. Organizations using OCR report up to 99.5% accuracy in data extraction, while processing times drop from hours to minutes.
Combining OCR with EDI creates a powerful ecosystem for document management. This integration streamlines electronic invoice processing, automates data capture, and ensures seamless information flow between trading partners. Companies benefit from faster processing cycles, reduced errors, and stronger compliance measures.
Commport Communications leads this technological advancement by integrating OCR capabilities within their EDI solutions, helping businesses automate electronic invoicing and streamline document processing across their supply chains.
Remember, successful digital transformation requires the right tools and implementation strategy. Start small, measure results, and scale your OCR implementation based on proven success. This approach ensures maximum return on investment while maintaining operational efficiency.
Commport B2B Integration Solutions
Frequently Asked Questions
OCR technology goes beyond simple scanning by converting images of text into editable and searchable digital content. While scanning creates a digital image, OCR analyzes the image to recognize and extract text, allowing for editing, searching, and manipulation of the content.
OCR implementation offers several key benefits: it significantly reduces manual data entry time, improves accuracy by minimizing human errors, and provides cost savings through automation. It also enables faster processing of large document volumes and improves data accessibility.
Yes, advanced OCR systems, particularly those using Intelligent Character Recognition (ICR), can process handwritten text. These systems employ sophisticated algorithms and machine learning techniques to interpret various handwriting styles, though accuracy may vary depending on the clarity of the handwriting.
OCR enhances EDI systems by automating the capture and validation of data from paper documents or non-standardized digital formats. This integration streamlines electronic invoice processing, reduces delays, and improves compliance by ensuring accurate data transfer between trading partners.
OCR is widely used across various sectors, with significant impacts in banking and finance for document automation, healthcare for digitizing medical records and prescriptions, legal services for document digitization and e-discovery, and retail and supply chain for inventory management and invoice processing.



